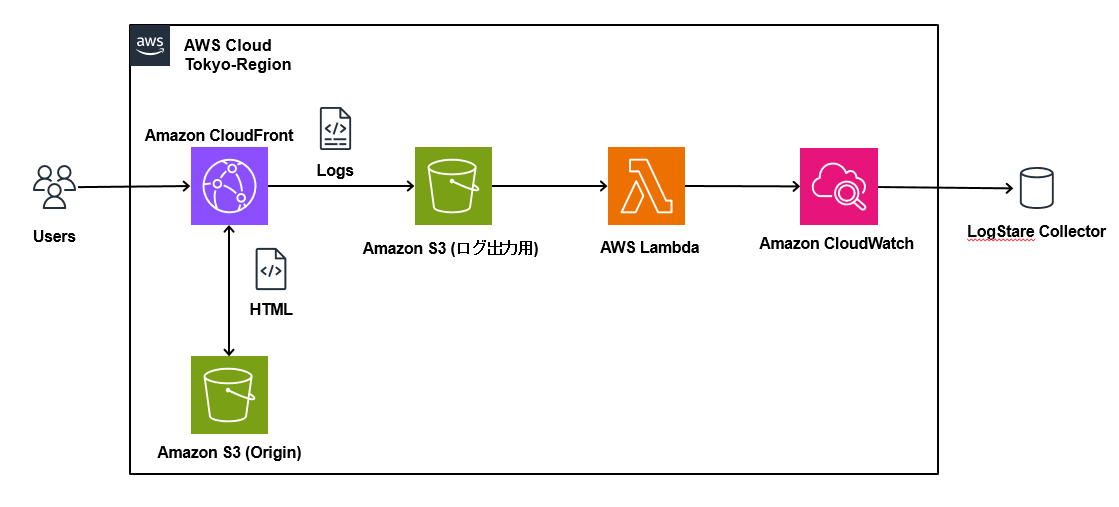
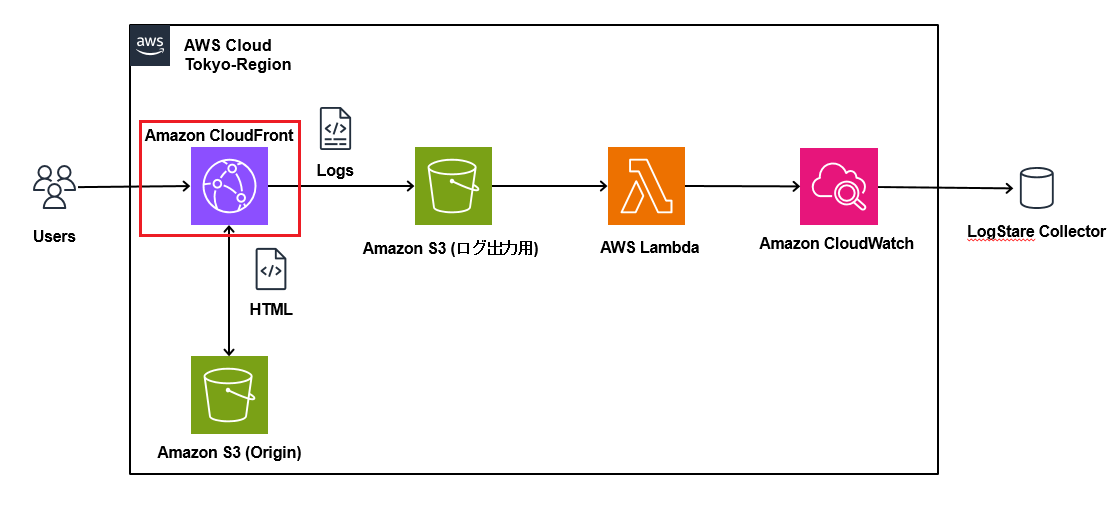
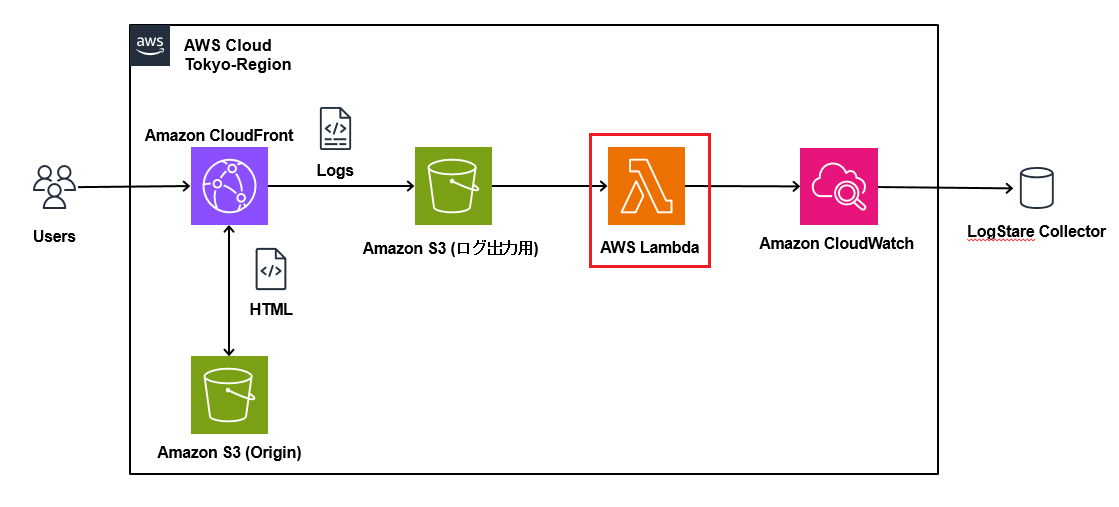
当記事では、LogStare Collector(LSC)のCloudWatch Logs収集機能を用いてCloudFrontログを取得する方法について記載します。

CloudFrontはCloudWatch Logsに直接ログを出力することが出来ず、S3にしか出力できません。
そのため、S3に出力されたログを、Lambdaを用いてCloudWatch Logsに集約し、LSCで収集します。
2024年11月20日のCloudFrontの仕様変更に伴い、
CloudFrontからCloudWatch Logsに直接ログを出力することが可能になりました。
詳細は「Amazon CloudFront がアクセスログの追加のログ形式と出力先をサポートするようになりました」をご確認ください。
- 本書の手順では複数のAWSサービスを利用します。
それぞれ利用料金が発生いたしますので、予めご了承ください。 - 本書は、株式会社LogStareが2023年12月に行った検証をもとに記載しており、
詳細な手順等についてはAWSのドキュメント等についてもあわせてご参照ください。 - 本書記載の内容により発生したいかなる損害、想定外のAWS利用料金の発生等について、
当社株式会社LogStareは一切の責任を負いかねます。予めご了承ください。 - 本書記載の手順を実行後の完成後の状態は以下の通りです。
目次
オリジン用S3の構築
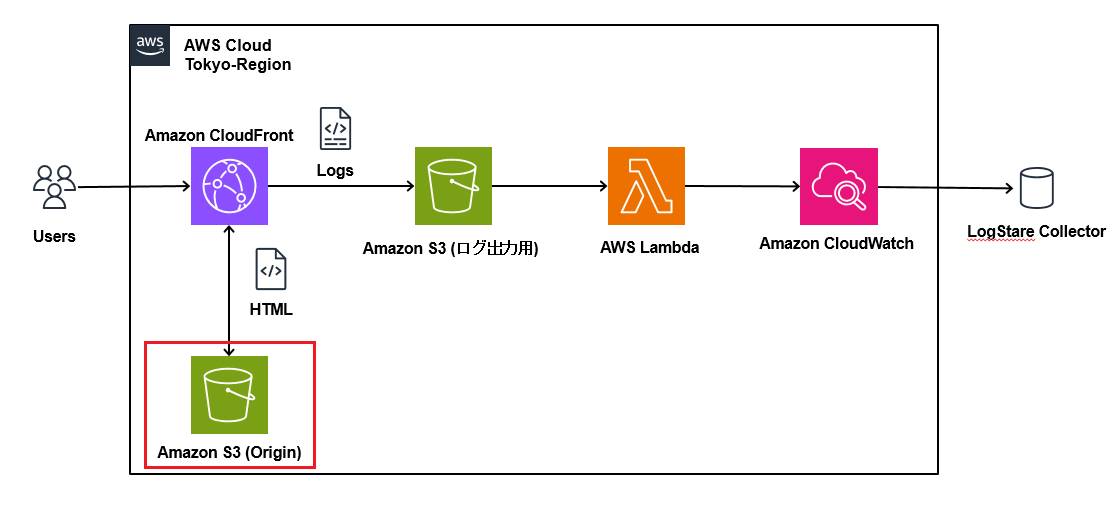
CloudFrontでコンテンツを配信するためのS3を構築し、それをオリジンとして用います。
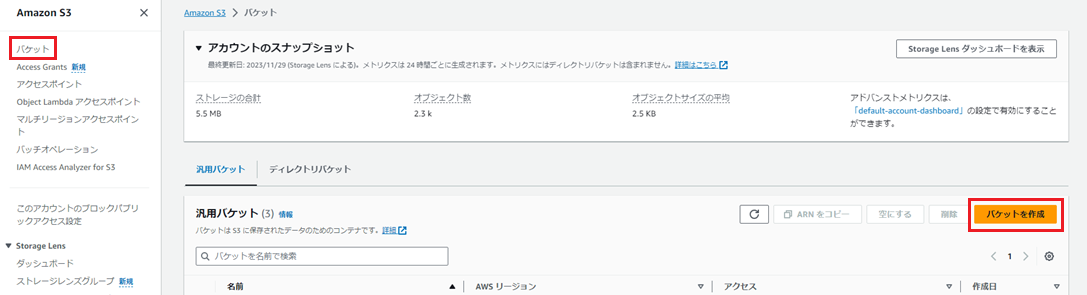
コンソールから「S3」サービスを選択し、メニューより「バケット」を選択します。
次に、「バケットを作成」を押下します。
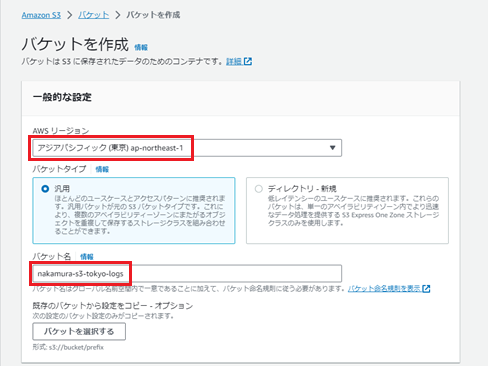
「AWSリージョン」は任意ですが、今回は「アジアパシフィック(東京)ap-norheast-1」を選択しました。
「バケット名」に任意の名前を入力します。
その他はデフォルトで結構です。
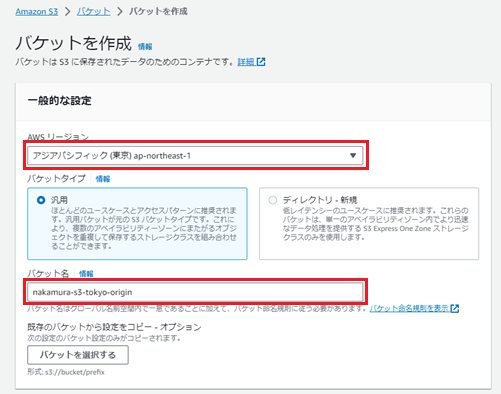
設定が完了したら「バケットを作成」を押下します。
次に、作成したs3バケットにオリジンとして用いるファイルをアップロードします。
作成したs3バケットを押下します。
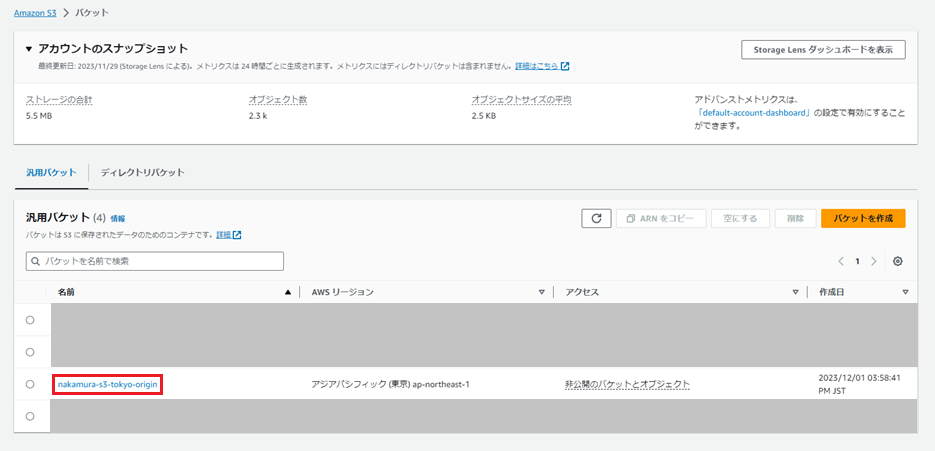
「アップロード」を押下します。
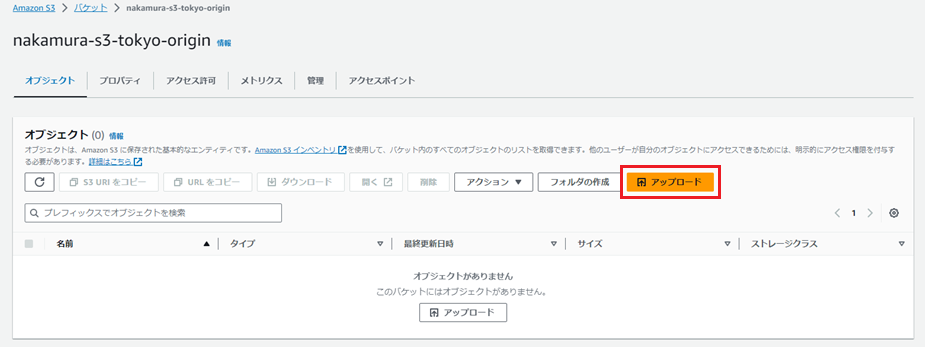
ここにオリジンとして配信したいファイルをアップロードします。
特に指定はないですが、今回はindex.htmlという名前のhtmlファイルを用意しました。
中身は以下の通りです。
<!DOCTYPE html> <html lang="ja"> <body> origin. </body> </html>
上記のファイルをドラッグアンドドロップし、「アップロード」を押下します。
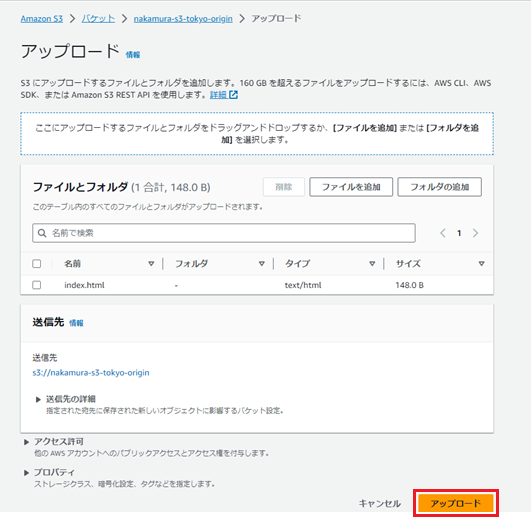
これでアップロードが完了しました。
CloudFrontの構築
次にCloudFrontを構築していきます。
コンソールから「CloudFront」サービスを選択し、「ディストリビューションを作成」を押下します。
「オリジンドメイン」に先ほど作成したS3を入力します。「名前」は任意です。
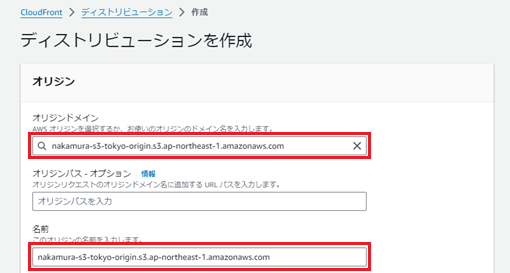
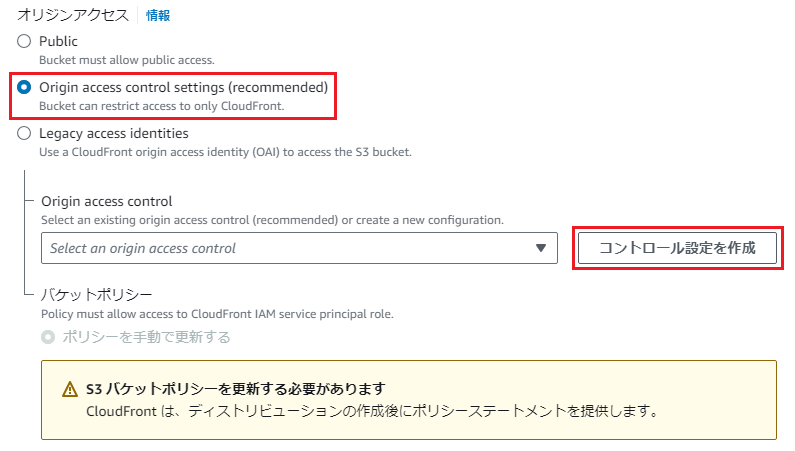
「オリジンアクセス」に「Origin access control settings (recommended)」を選択し、「コントロール設定を作成」を押下します。
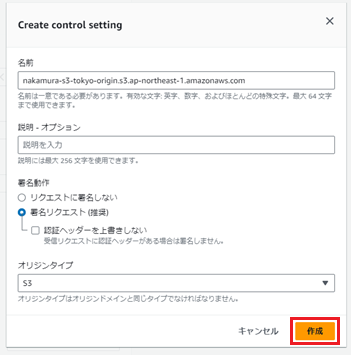
特に変更せず「作成」を押下します。
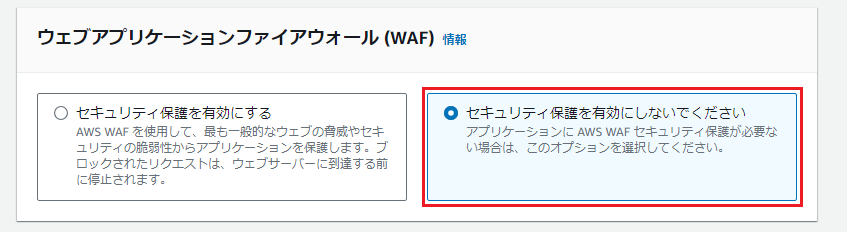
「ウェブアプリケーションファイアウォール(WAF)」は、今回はオフにしますが必要に応じて有効にしてください。
「料金クラス」は料金を抑えるために「北米、欧州、アジア、中東、アフリカを使用」を選択しました。
「デフォルトルートオブジェクト」はオプション設定ですが、ルート(/)にアクセスしたときにS3にアップロードしたindex.htmlを表示させるために以下のように設定しました。
その他の設定はデフォルトで結構です。
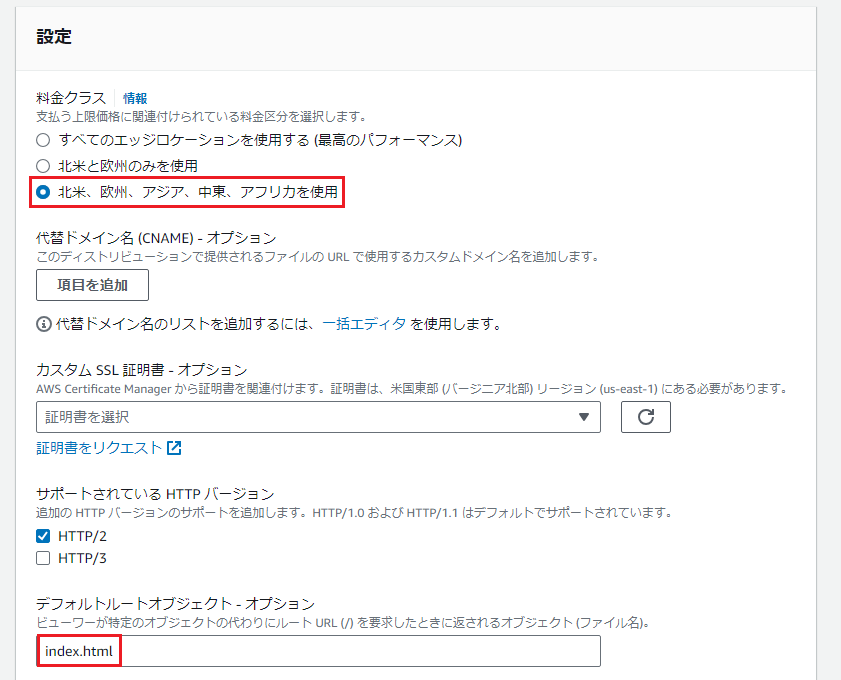
設定が完了したら、「ディストリビューションを作成」を押下します。
CloudFrontの作成が完了すると以下のような警告が出てきます。
これは、S3のバケットに適切な権限を設定する必要があるということを示しています。
「ポリシーをコピー」を押下し、「S3バケットの権限に移動してポリシーを更新する」を押下します。
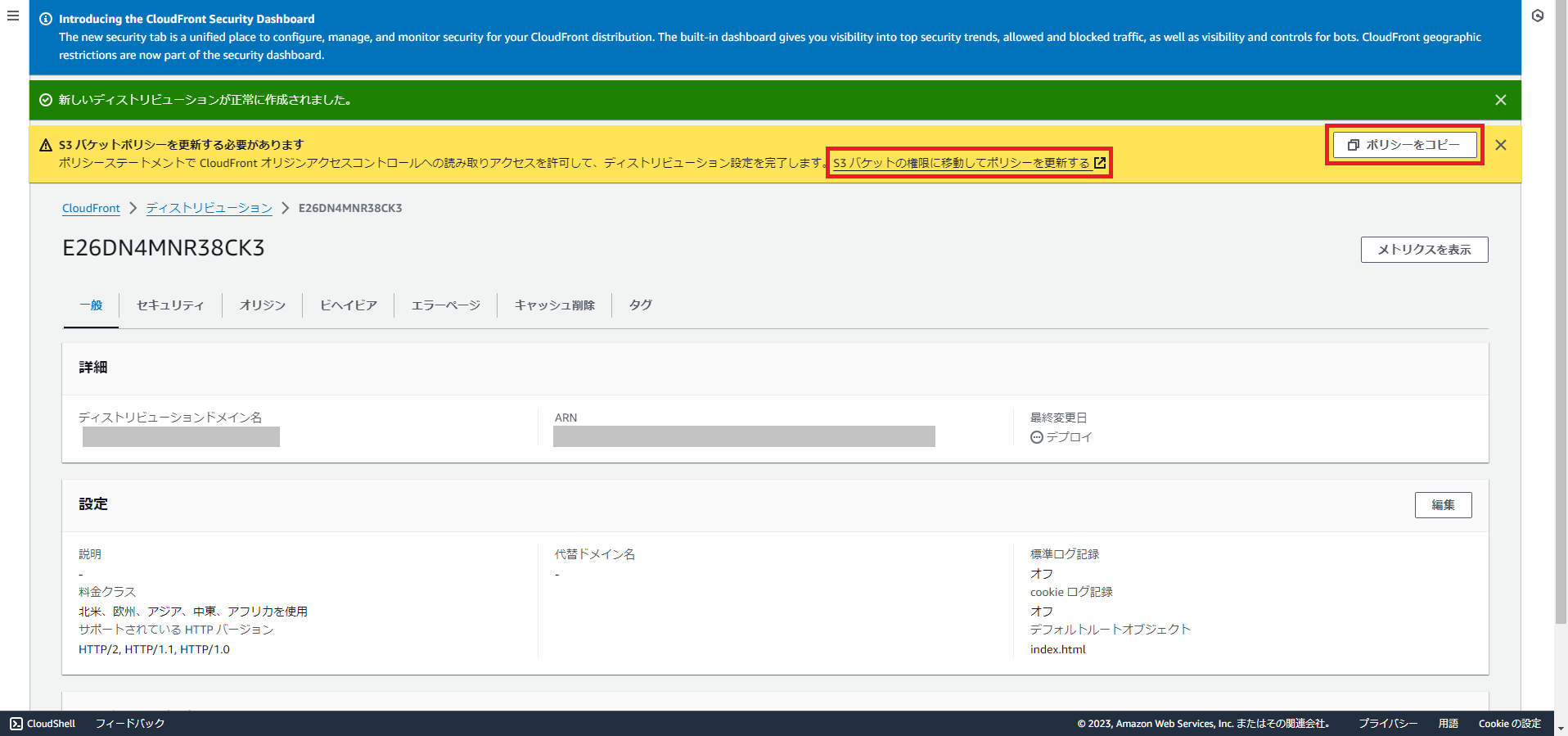
S3のアクセス許可の設定画面に遷移しますので、「バケットポリシー」の「編集」を押下します。
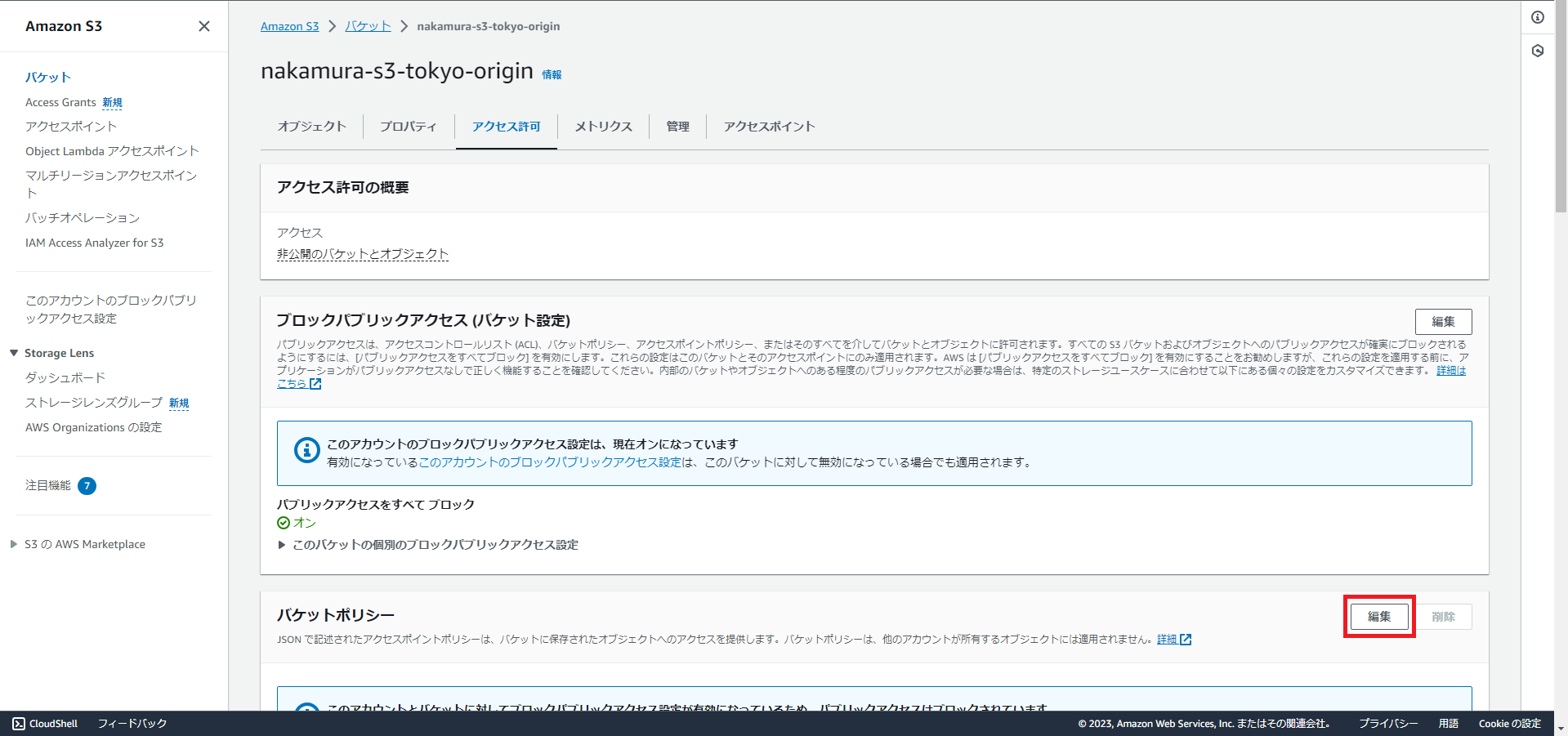
コピーしたポリシーを貼り付け、「変更の保存」を押下します。
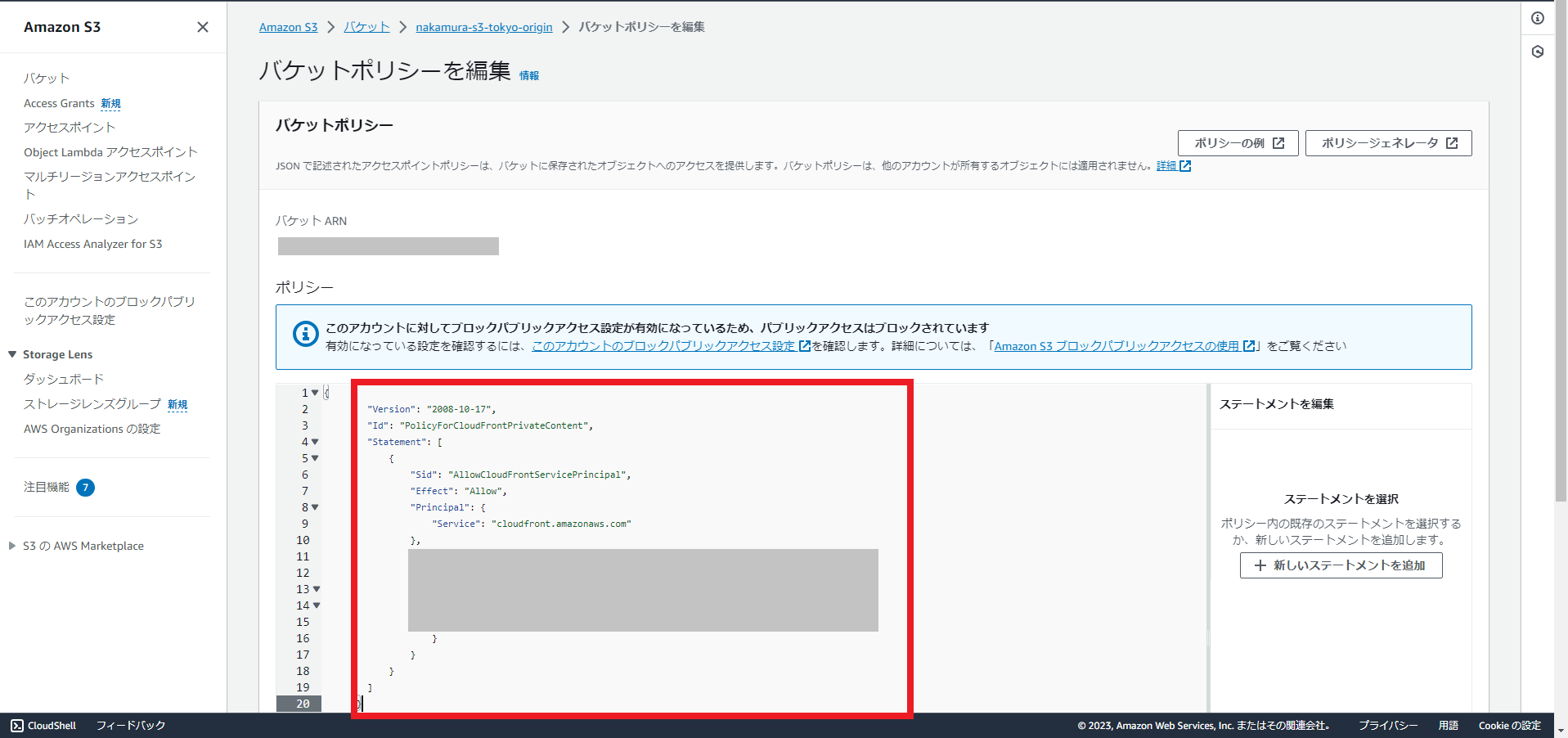
ここまで完了すると、ブラウザでCloudFrontの「ディストリビューションドメイン名」にアクセスすると、S3にアップロードしたhtmlファイルを見ることが出来ます。

ログ出力用S3の構築
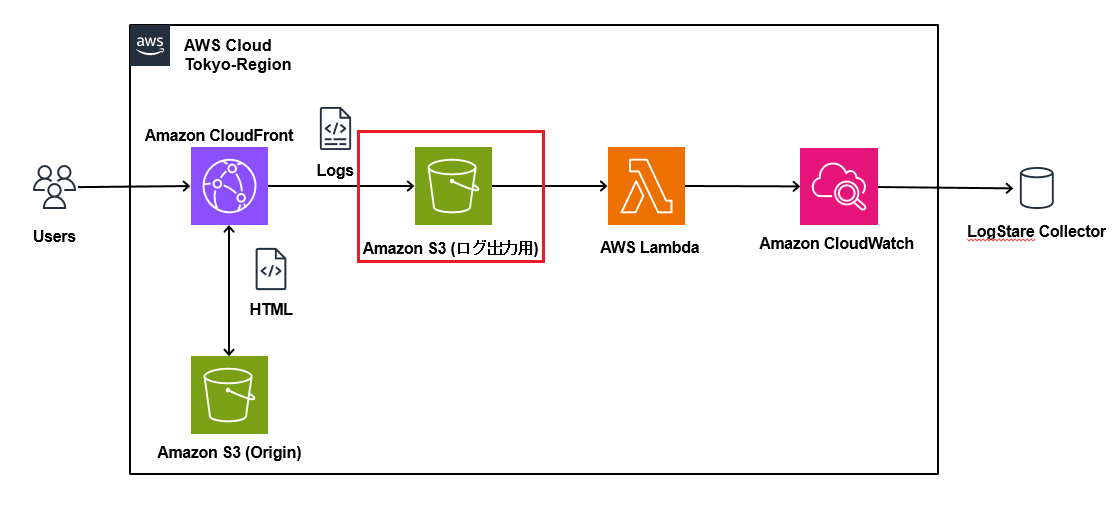
次に、CloudFrontのログを出力するためのS3を構築します。(Amazonからオリジン用のS3とログ用のS3を分けるように推奨されているため、新しくS3を構築します。)
コンソールから「S3」サービスを選択し、「バケットを作成」を押下します。
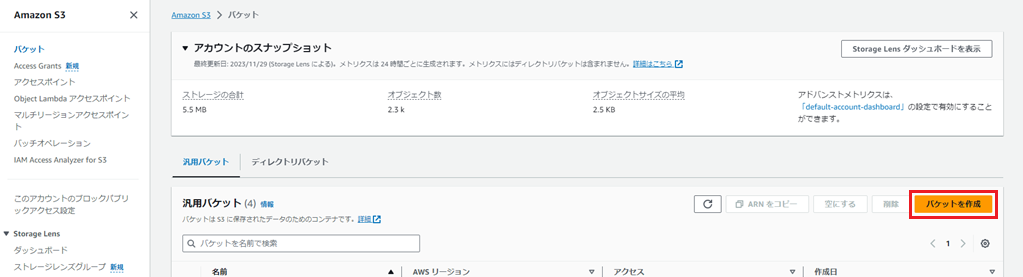
「AWSリージョン」は「アジアパシフィック(東京)ap-northeast-1」を選択しました。
リージョンによってはCloudFrontのログを出力することが出来ないため、詳しくは「標準ログ用の Amazon S3 バケットの選択」をご確認下さい。
バケット名は任意の名前を入力します。
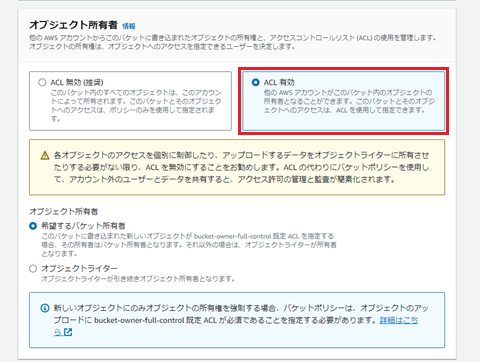
「オブジェクト所有者」は「ACL有効」を選択します。
(2023年4月以降はACLを有効にする必要があります。詳しくは「標準ログの構成とログファイルへのアクセスに必要な権限」をご確認下さい。)
公式ドキュメントの記載はありませんでしたが、検証を行ったところ、ACL無効でも設定は可能でした。
その他はデフォルトで結構です。設定が完了したらページ下部にある「バケットを作成」を押下します。
次に、CloudFrontの設定を変更し、ログがS3に出力されるようにします。
作成したCloudFrontを押下します。
設定の編集を押下します。
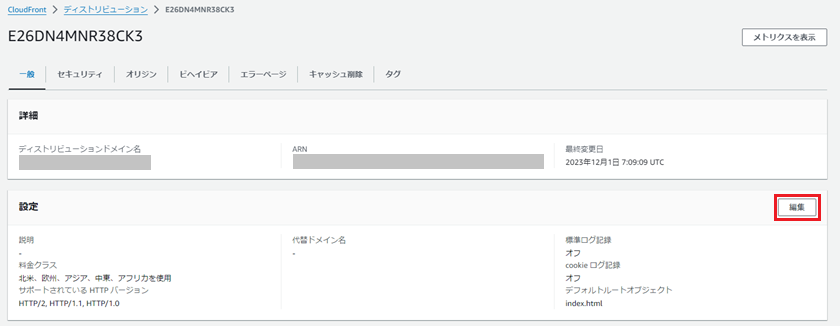
「標準ログ記録」をオンにし、「S3バケット」にログ出力用に作成したS3を指定します。
設定が完了したら「変更を保存」を押下します。
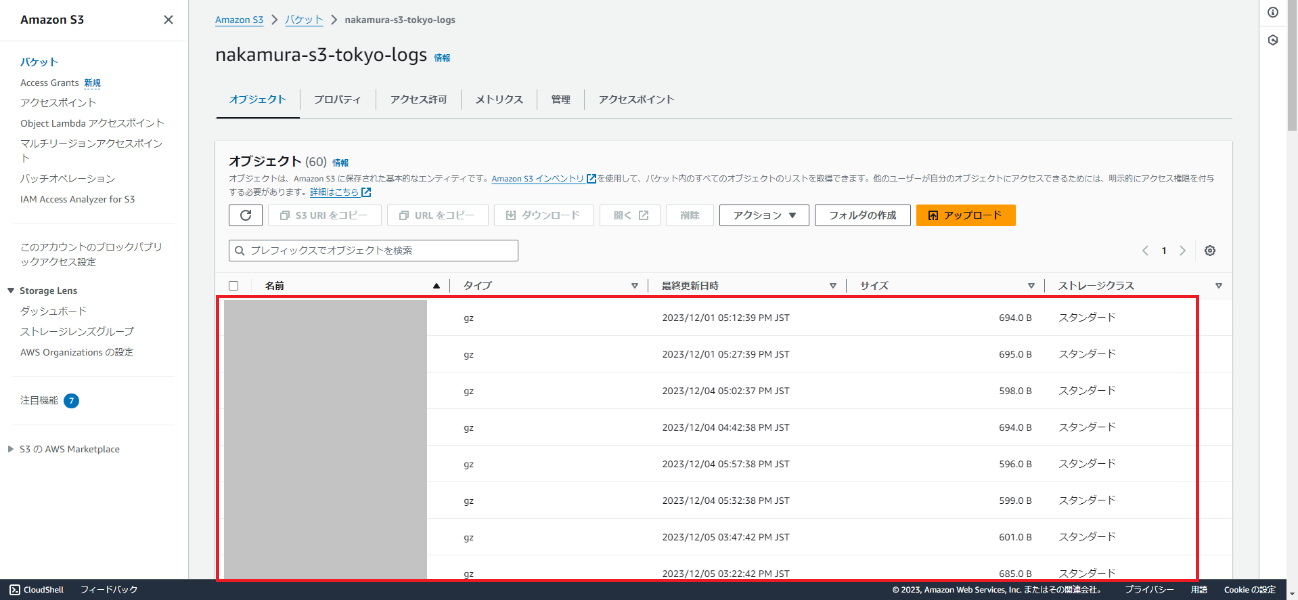
ここまで完了するとログ出力用のS3にCloudFrontのログが出力されるようになります。(ディストリビューションドメイン名にアクセスしてから、ログが出力されるまでにはある程度時間がかかります。)
CloudWatch Logsの構築
次に、ログを出力するCloudWatch Logsを構築します。
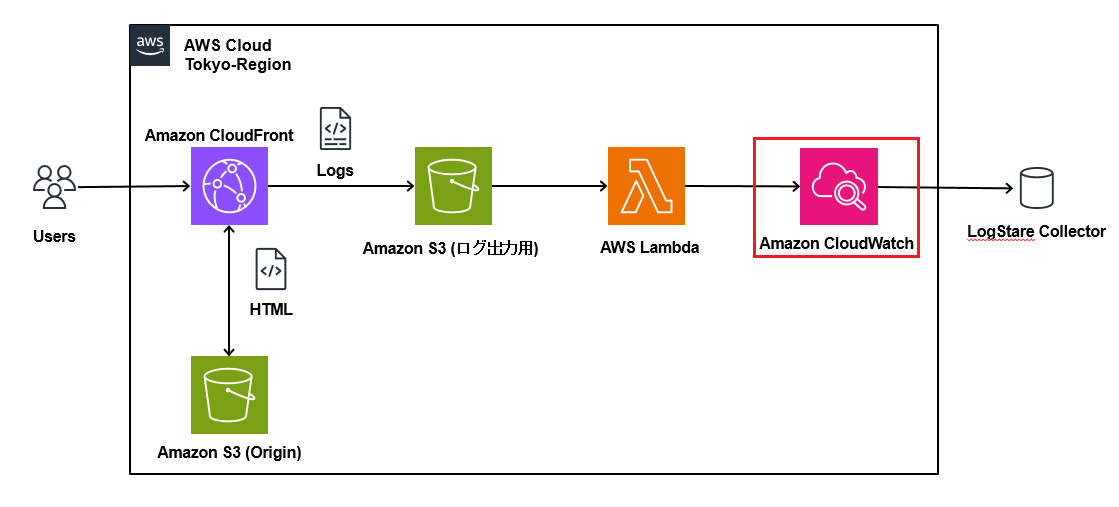
初めにロググループを作成します。コンソールから「CloudWatch」サービスを選択し、ログ>ロググループから「ロググループを作成」を押下します。

「ロググループ名」に任意の名前を入力し、特に設定は変更せずに「作成」を押下します。
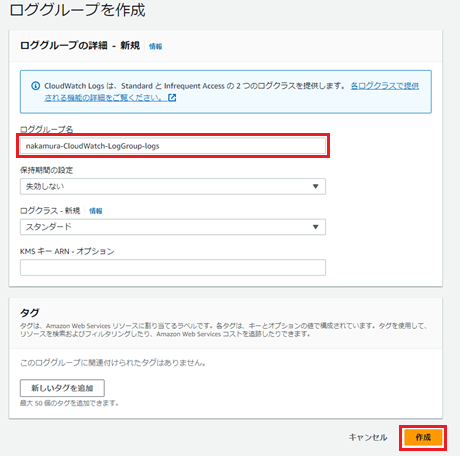
次にログストリームを作成します。作成したロググループを押下します。
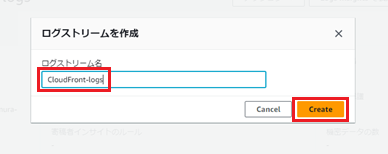
「ログストリームを作成」を押下します。
任意のログストリーム名を入力し、「Create」を押下します。
Lambda関数の構築
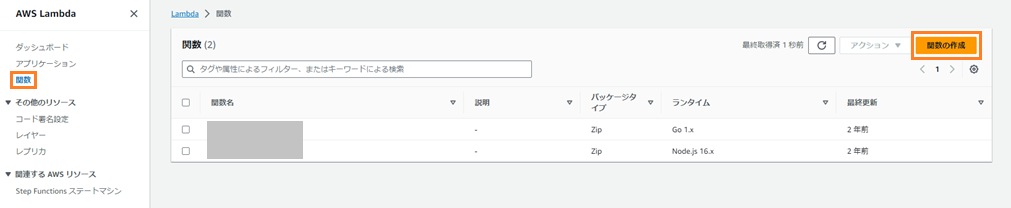
次に、S3にあるログファイルをCloudWatch Logsに出力するLambda関数を作成します。
コンソールより「Lambda」サービスを選択し、メニューより「関数」を押下します。
右上の「関数の作成」を押下します。
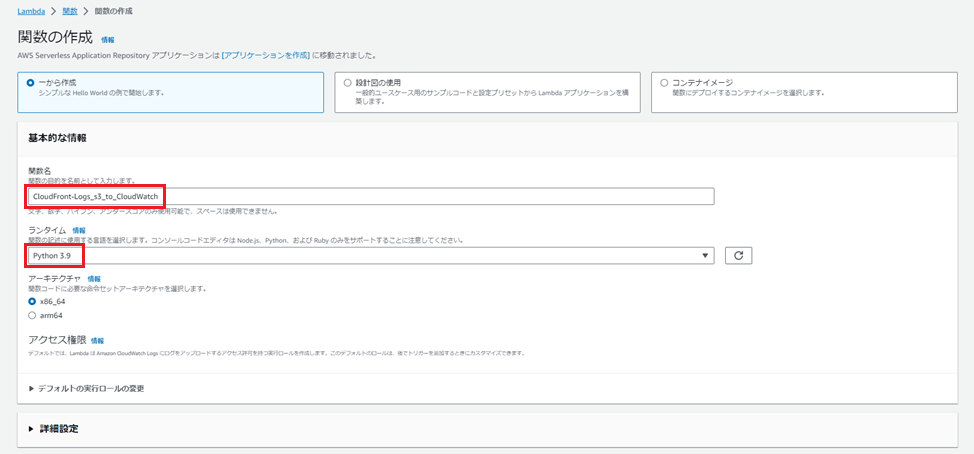
「関数名」に任意の名前を入力し、ランタイムは「Python 3.9」を選択します。
その他はデフォルトで結構です。
設定が完了したら「関数の作成」を押下します。
次にトリガーの設定を行います。
「トリガーを追加」を押下します。
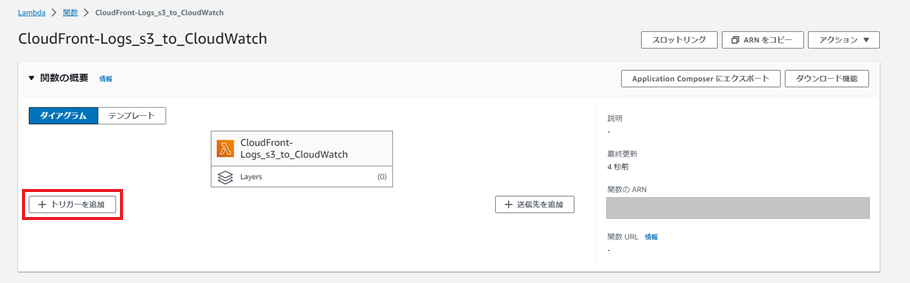
「ソース」にS3を選択し、「Bucket」はログ出力用に作成したS3を指定します。
「Event types」はPUTを設定します。
「Recursive invocation」にチェックを入れ、「追加」を押下します。
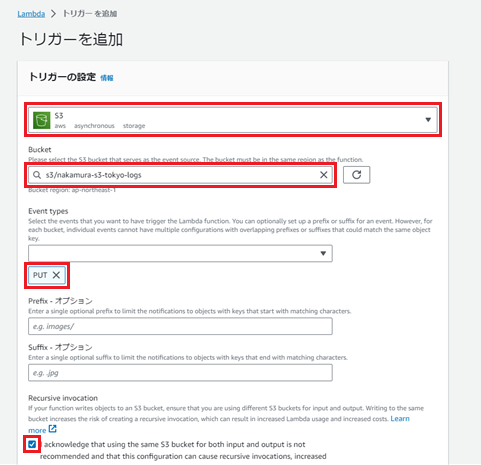
トリガーが作成され、S3にログファイルが出力されたタイミングでLambda関数が実行されるようになりました。
次に、S3にあるログファイルをCloudWatch Logsに出力するコードを入力します。
「コード」を押下し、以下のコードを入力します。logGroupNameとlogStreamNameは環境に応じて書き換えてください。
(コードは以下のサイトを参考にしました。
- Lambda (Python) から特定のログストリームにログを書こうとして苦戦した2つのポイント - Qiita
- Python (Boto3) @ Lambda で CloudWatch Logs の特定のログストリームにログを出力する - Qiita
- LambdaでS3上に出力されたログをCloudWatch Logsに取り込んで監視する | mooapp (wordpress.com)
- s3に圧縮ファイルがアップされた際に、解凍して要素をCloudWatchLogsに出力するLambda Function(python版)
)
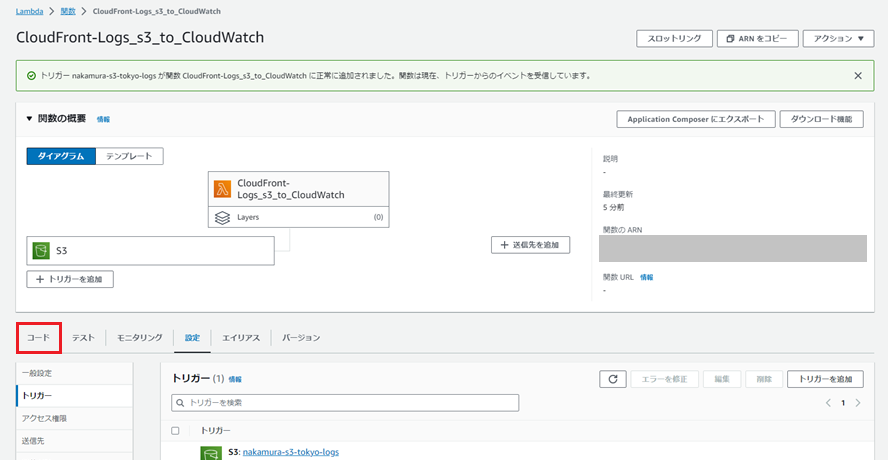
import json
import urllib.parse
import boto3
import time
import gzip
import os
print('Loading function')
s3 = boto3.client('s3')
logs_client = boto3.client('logs')
## 変数
logGroupName = "nakamura-CloudWatch-LogGroup-logs"
logStreamName = "CloudFront-logs"
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
file_name = os.path.basename(key)
file_path = os.path.join('/tmp', file_name)
s3.download_file(bucket, key, file_path)
f=gzip.open(file_path,'rt')
file_content=f.read()
f.close()
list = file_content.splitlines()
for index,item in enumerate(list):
if index > 1 :
put_logs(logs_client,logGroupName,logStreamName,item)
#delete file in tmp
if os.path.isfile(file_path):
os.remove(file_path)
return 'function complete'
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
def put_logs(client, group_name, stream_name_prefix, message):
try:
exist_log_stream = True
log_event = {
'timestamp': int(time.time()) * 1000,
'message': message
}
sequence_token = None
try:
if exist_log_stream == False:
create_log_stream_response = client.create_log_stream(
logGroupName = group_name,
logStreamName = stream_name_prefix)
exist_log_stream = True
if sequence_token is None:
put_log_events_response = client.put_log_events(
logGroupName = group_name,
logStreamName = stream_name_prefix,
logEvents = [log_event])
else:
put_log_events_response = client.put_log_events(
logGroupName = group_name,
logStreamName = stream_name_prefix,
logEvents = [log_event],
sequenceToken = sequence_token)
except client.exceptions.ResourceNotFoundException as e:
exist_log_stream = False
except client.exceptions.DataAlreadyAcceptedException as e:
sequence_token = e.response.get('expectedSequenceToken')
except client.exceptions.InvalidSequenceTokenException as e:
sequence_token = e.response.get('expectedSequenceToken')
except Exception as e:
print(e)
except Exception as e:
print(e)
入力が完了したら「Deploy」を押下します。
次に、Lambda関数に権限を付与します。
設定>アクセス権限から「ロール名」を押下します。
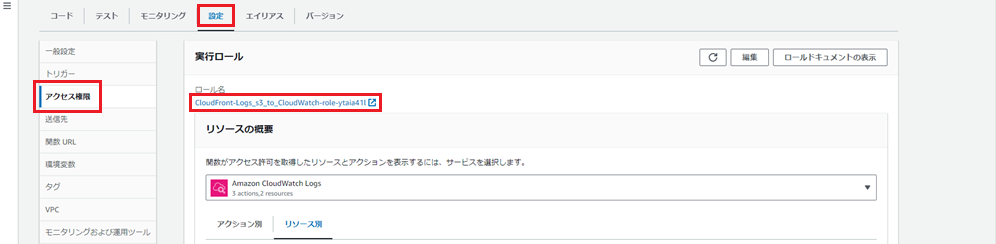
IAMの設定画面に遷移しますので、「設定を追加」の「インラインポリシーを作成」を押下します。
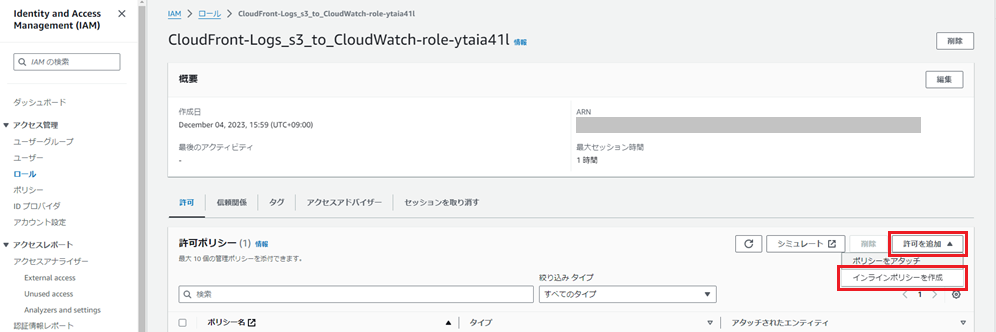
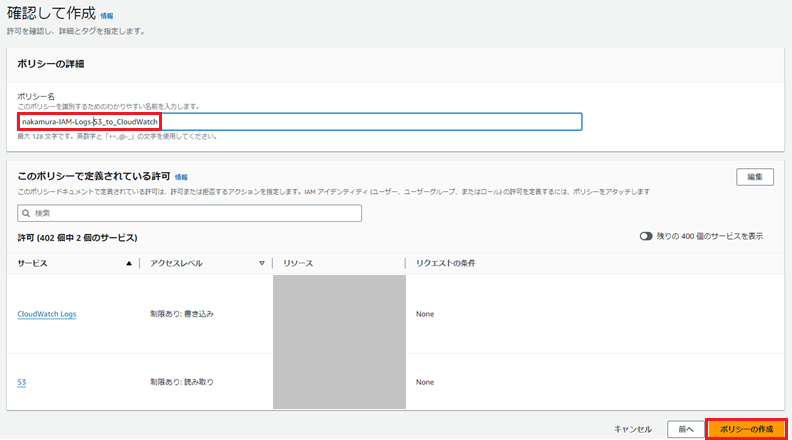
ここで、S3に「GetObject」、CloudWatch Logsに「PutLogEvents」の権限を付与します。
ARNは環境にあったものを設定してください。ポリシー名に任意の名前を入力し、「ポリシーの作成」を押下します。
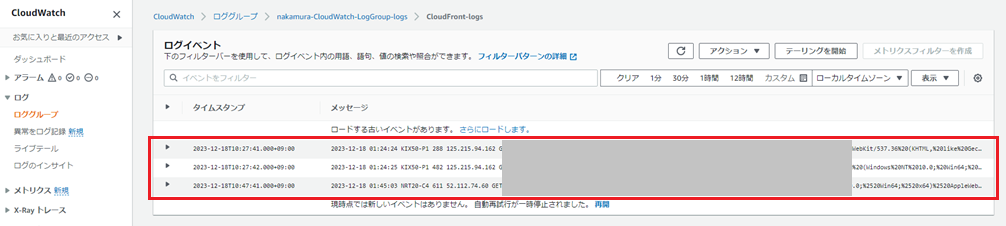
ここまで完了すると、CloudWatch Logsにログが出力されるようになります。
LogStare Collectorの構築
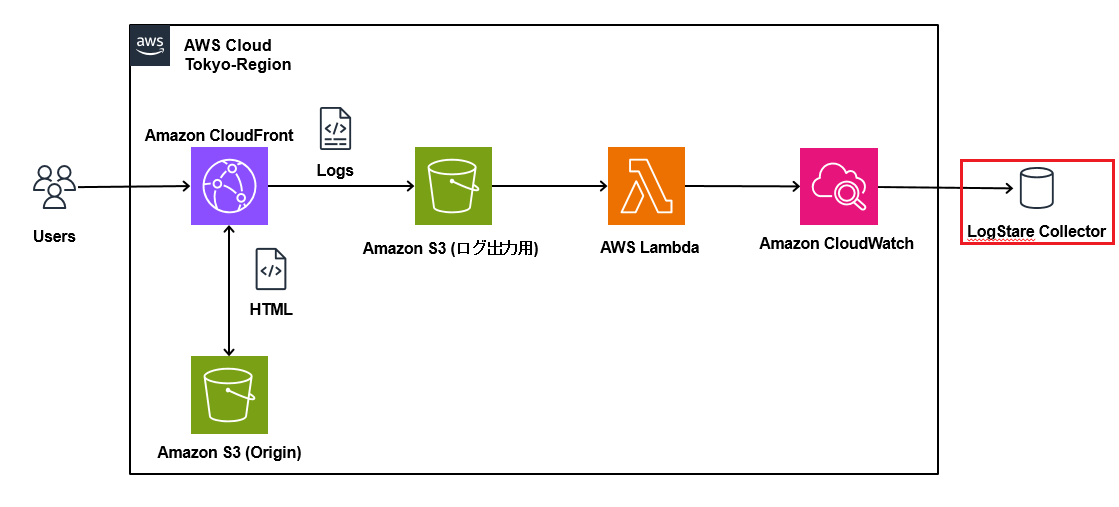
次に、CloudWatch Logsのログを収集できるようにLSCを構築します。
詳しい設定方法は「LogStare CollectorでのAWS WAFログの取得方法とログレポート」の「LogStare Collector側の設定」をご参照ください。
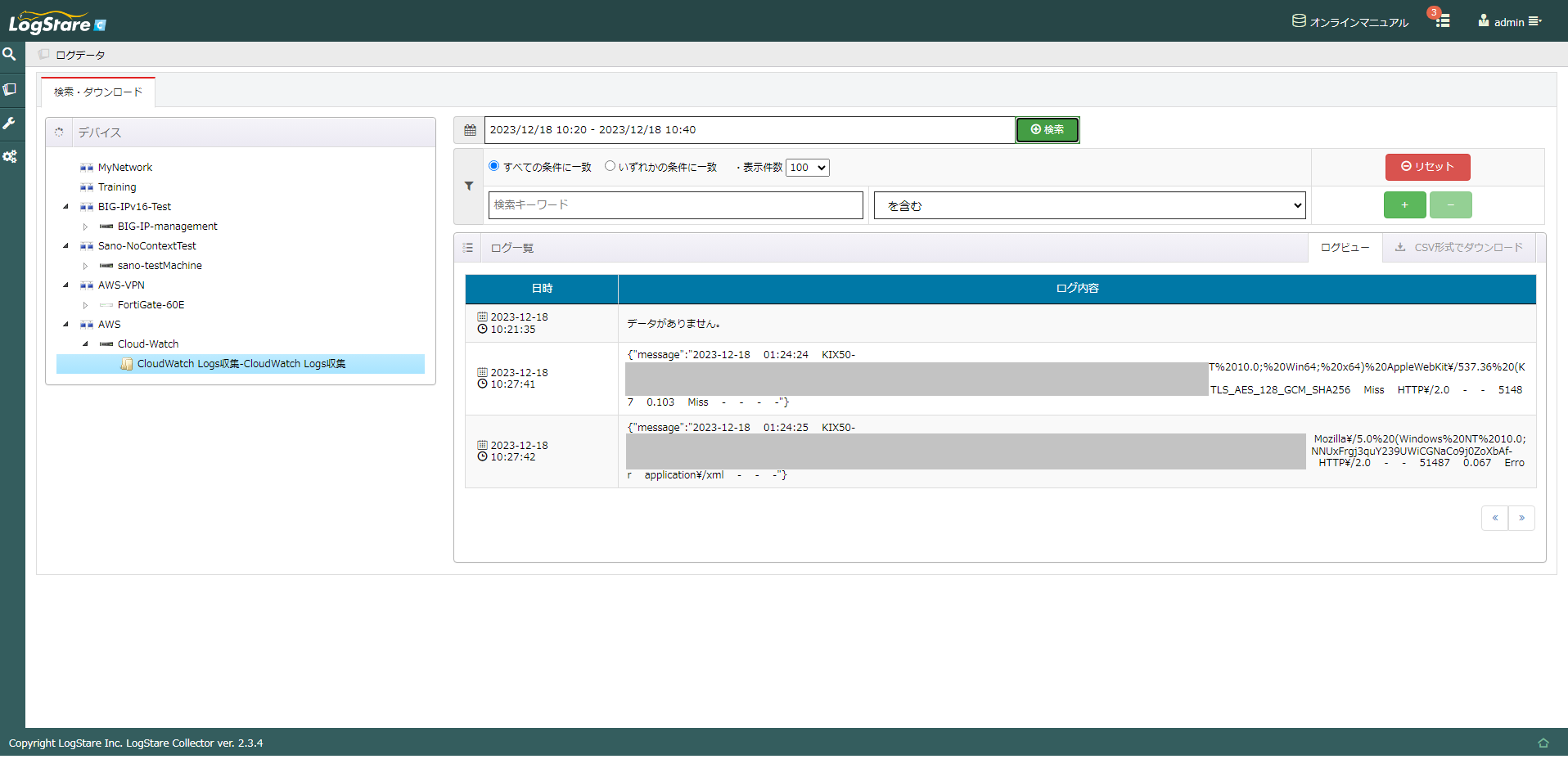
LSCの設定が完了すると、以下のようにログが見ることが出来ます。
おわりに
今回はLSCでのCloudFrontログの取得方法をご紹介いたしました。
手順は長くなってしまいましたが、S3にしか出力できないサービスのログもLSCで取得することが出来るということが分かっていただけたかと思います。
CloudFront以外のサービスのログもLSCに出力することが出来るため、AWSのログ管理にLSCをご活用いただけたら幸いです。

記載されている会社名、システム名、製品名は一般に各社の登録商標または商標です。
当社製品以外のサードパーティ製品の設定内容につきましては、弊社サポート対象外となります。